Harry Potter Word Frequency
In language acquisition, there’s the idea of the most common words in a language. It can be interesting to know this when learning a new language. I’ll try to analyze Harry Potter and the Philosopher’s Stone in order to show word frequency and how many of the 1000 most common English words are represented in the book, so one has an idea how much of the book is possible to read when knowing only this set of words (of course it’s a simplification, but an interesting one).
Plain Text
Number one task I have is to get the book in plain text, so I can process it. I’ve found it online on this website. To see just first 10 lines to get an idea, the file looks like this:
Harry Potter and the Sorcerer's Stone
CHAPTER ONE
THE BOY WHO LIVED
Mr. and Mrs. Dursley, of number four, Privet Drive, were proud to say
that they were perfectly normal, thank you very much. They were the last
people you'd expect to be involved in anything strange or mysterious,
because they just didn't hold with such nonsense.
Clearing the Data
When I have a look at the file, there’re a few problems with the text:
- some words use both
[A-Z]and[a-z]ranges - there are some numbers (page numbers, etc.) that I don’t consider as numbers
- there are empty lines
- there’s punctuation that can spoil individual words
- but not all
[[:punct:]]is problematic - e.g.you'veis alright
I need to get rid of all these data, so I have a “clean” text as input for frequency analysis.
Upper to Lowercase
This is fairly easy to do:
$ cat hpps | tr '[A-Z]' '[a-z]'
Done.
Punctuation
I want to delete some punctuation:
$ sed -e "s/[,;:\!?.\"()-]//g" hpps
No Empty Lines
Empty lines spoil the data as well, get rid of them:
$ grep -v "^$" hpps
Getting rid of numbers
I need get rid of numbers. This turns out to be a little bit of problem as I’ve discovered some of the numbers are juxtaposed to other characters such as '. The solution is to use this after other steps as well.
$ grep -v -E "^[0-9]+$"
After these steps, first 10 lines look like this:
harry potter and the sorcerer's stone
chapter one
the boy who lived
mr and mrs dursley of number four privet drive were proud to say
that they were perfectly normal thank you very much they were the last
people you'd expect to be involved in anything strange or mysterious
because they just didn't hold with such nonsense
mr dursley was the director of a firm called grunnings which made
drills he was a big beefy man with hardly any neck although he did
have a very large mustache mrs dursley was thin and blonde and had
That’s much better, but I still want to transform the data a bit more.
Word per Line
Let’s put each word on a single line:
$ sed -e "s/[[:space:]]/\n/g"
But the problem now is some of the “words” look like this:
'please'
's'
'f'
'gar'
'yes
'jordan
'nmat
'dumbledore
'til
'hocus
'cause
I don’t want to consider these to be words since I don’t like the apostrophe. Let’s clean it further:
$ grep -v "^'"
and at the end:
$ grep -v "'$"
Now it looks much cleaner:
harry
potter
and
the
sorcerer's
stone
chapter
one
the
boy
If I try to find numbers:
$ grep [0-9]
I get:
4
4
17
1
31
3
0
1
2
3
4
1
2
382
1945
31
3
1473
1945
1709
1637
90
I filter out such lines again:
$ grep -v -E "^[0-9]+$"
The same has to be done with empty lines:
$ grep -v "^$"
Finally, I consider the input data clean. Let’s see some basic statistics:
$ wc -l hpps_cleaned
76967 hpps_cleaned
That’s how many words are in the book :) The file could be downloaded here.
Most Frequent Words
I can finally count frequency of each words. I’ll use awk for that and sort the output:
$ awk '{!word[$1]++} END{for (w in word) {print w,word[w]}}' hpps_cleaned | sort -k2 -h -r | head -10
the 3621
and 1914
to 1852
a 1682
he 1526
of 1254
harry 1208
was 1182
it 1022
in 962
The first most common words in the book are not a big suprise. There’re mostly prepositions, articles, and one name (I should have got rid of that). The complete sorted list could be downloaded here.
If I count the number of unique words, I get:
$ wc -l hpps_frequency_sorted
5990 hpps_frequency_sorted
Again, there are “words” like pomfrey's which are not ideal from at least two reasons:
- they contain names
- they contain short forms (
's,'ve, etc.)
However, I still consider this list a pretty decent approximation.
1000 Most Common English Words
Another interesting point of view could be to have a look at the first 1000 most common English words and see how many of them are represented in this text. Such a list could be found on different places, they even vary a bit since the underlying inputs could have been different. For my analysis, I’ve used this one. You actually get 10000 most common English words, so I cut the list:
$ awk '(NR <= 1000) {print}' 10000
The rest is to go over my harry-potter file and this 1000 file and perform some counting on it:
$ awk '(FILENAME == "1000") {!x[$1]++} (FILENAME == "hpps_cleaned") {!y[$1]++} END{for (w in x) { if(y[w]) {c++}} print c}' 1000 hpps_cleaned
615
615 words from the list of the 1000 most common English words are in the Harry Potter book. I can see how much of the original text is represented by these 615 words:
$ awk '(FILENAME == "1000") {!x[$1]++} (FILENAME == "hpps_cleaned") {!y[$1]++} END{for (w in x) { if(y[w]) {c+=y[w]}} print c}' 1000 hpps_cleaned
47216
If someone learns the list of the 1000 most common English words, they can read about 61 % of Harry Potter and the Philosopher’s Stone. I can calculate the same thing for a few more values of the most common English words and see what’s gonna happen to the coverage in the book:
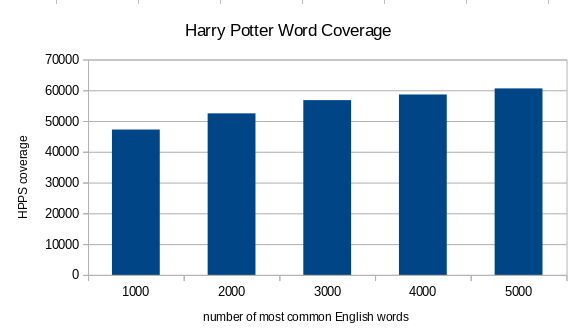
So for the 5000 most common English words, the coverage of Harry Potter and the Philosopher’s Stone is nearly 79 %. Still, it doesn’t mean you can read the book easily, 79 % of the text understood is not enough for easy comprehension. Another thing to notice here is the developement of these numbers. The more words I learn from the list of the most common English words, the higher the coverage, but it’s not a linear function. It suggests the strategy of learning frequency words is not always effective. The more one knows, the more one needs to study low frequency words that are outside of the range of any list of most common words.
Next, I can have a look at the words that are outside of the range of the 1000 most common English words according to my list presented above:
$ awk '(FILENAME == "1000") {!x[$1]++} (FILENAME == "hpps_cleaned") {!y[$1]++} END{for (w in y) { if(! x[w]) {print w}}}' 1000 hpps_cleaned
These are the words in the Harry Potter book but outside of the 1000 most common English words. That’s the remaining 5375 unique words. The complete list cound be downloaded here.
If I take a look as some of them:
that's
blackpool
closer
coats
dampen
wriggles
vanished
fastenings
elephant
died
cage
reason
morning
globes
curiously
toads
tulips
staffroom
bobbing
squashy
hurts
lord
looming
mmm
plates
snape
I still can see the underlying data could be improved. There’re names and short forms, both of which spoil the data and provide less accurate result. The rest are words not so frequent or words related to this specific wizarding world (like toads (sort of anyway)).
Conclusion
There could be much more to say about this. You can play around with the data to find more. I’ll, however, bring it to a conlusion here. What I see here is mostly language learning advice, since that’s why I started on this article in the first place.
Many articles and/or advice say that knowing just a few thousands of the most common English words is enough. I, based on this article, disagree. Even with the 5000 most common English words, one can comprehend only roughly 79 % of the book in question. That’s not enough for easy and pleasurable reading. One simply has to study even low frequency words that are outside of this range. The article even suggests that the strategy proves inefficient after a few thousands most common words learnt. The increments are simply too small.
From the point of view of the analysis, I can only say it’s amazing how much information one can get with just a couple of text processing tools. If I should do something similar again, I consider the data cleaning part the most important part of the whole process. If my input is correct, the results get even more precise.
NOTE: this article has left out many other points. E.g. you can’t really read much if you lack the knowledge of grammar.