Czech Regions and their Zip Codes
The Czech Republic currently consists of 14 regions. Zip codes in the CZE consist of 5 digits, first 2 - 3 of them representing a city, or (city) district. After first 3 digits, a space is usually written. It’s a common trap to think that it’s easy to go from a zip code to region. It’d make sense, but due to historical reasons, it’s not the reality.
First, one usually stumbles upon this psc.cz site. On the first glance, it looks pretty straightforward:
1 – PSČ Prahy
2 – PSČ Středočeského kraje
3 – PSČ Jihočeského a Západočeského kraje
4 – PSČ Severočeského kraje
5 – PSČ Východočeského kraje a části Jihomoravského kraje
6 – PSČ Jihomoravského kraje
7 – PSČ Severomoravského kraje
However, on the second glance, it doesn’t really fit the reality for a number of reasons:
- we have currently 14 regions, there’re only 9 on the list
- Severočeský region doesn’t really exist anymore, it’s split into Ústí nad Labem region and Liberec region; the same situation is with a couple of more regions on the list
- South Moravian region is said to have zip codes starting with 6, but in reality range 674 00 - 676 99 belongs to Vysočina region (that’s not even on the list), and another range 686 00 - 688 99 again belongs to Zlín region (again not even on the list)
All in all, there’s very little we can rely on with this list.
So, googling some more, we can actually find out that the above-mentioned list is not completely wrong, but those zip codes were valid for the Czechoslovakia, which is not a case anymore.
We can further read that since the dissolution of Czechoslovakia, there’s not been many attempts to adjust the zip codes for only the CZE, so we basically have part of what was valid for Czechoslovakia, making it hard to navigate when we currently have different regions.
If you click on the last link, there’s actually the following picture of the CZE divided into districts. The first 2 digits of zip code are shown on the map and they seem pretty accurate.
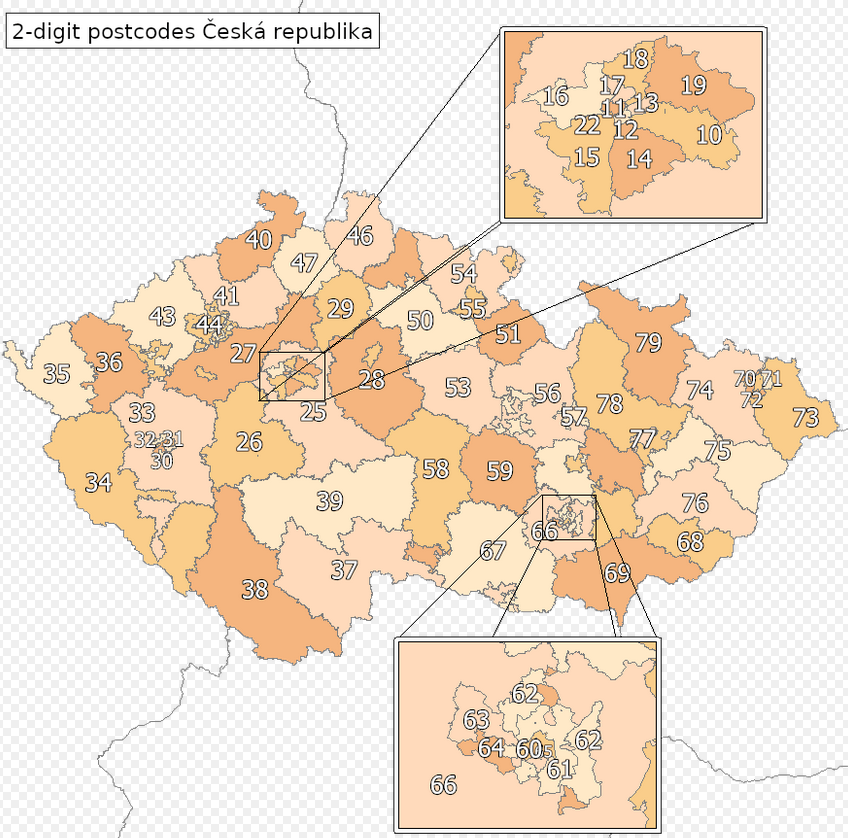
However, we do not really use districts anymore, so again, such a mapping between zip code digits and districts is not the most valid method today.
Finally, after a few more minutes of googling, this wiki page comes up. It’s finally a pretty detailed list of zip code ranges and what regions they belong to. What seems obvious looking at the list:
- the ranges of some regions are not really ordered, e.g. Zlín region seems to have a range of 750 00 - 769 99, but zip code 754** doesn’t really exist, and range 686 00 - 688 99 belongs to Zlín as well
So, the only chance is to focus on all those zip code ranges belonging to certain districts and then rellying on the fact that each district belongs to a particular region. This way, one can create something like I did in awk, a function that makes this mapping between zip codes and their regions happen:
#!/usr/bin/awk
# returns a Czech region name based on a zip code
# based on https://en.wikipedia.org/wiki/List_of_postal_codes_in_the_Czech_Republic
# zip codes in one of the following formats:
## 60000
## 600 00
# if a zip code doesn't exists, "NaN" is returned
function region(zip) {
switch (zip) {
# Prague region and special addresses belonging to Prague as well
case /^1[[:digit:]]{2}[ ]?[[:digit:]]{2}$/:
case /^21[[:digit:]]{1}[ ]?[[:digit:]]{2}$/:
case /^22[[:digit:]]{1}[ ]?[[:digit:]]{2}$/:
return "Prague";
break;
# Central Bohemian region
case /^25(0|1|2|3|4|6|7|8|9)[ ]?[[:digit:]]{2}$/:
case /^26(1|2|3|4|6|7|8|9)[ ]?[[:digit:]]{2}$/:
case /^27(0|1|2|3|4|6|7|8)[ ]?[[:digit:]]{2}$/:
case /^28(0|1|2|4|5|6|8|9)[ ]?[[:digit:]]{2}$/:
case /^29(0|3)[ ]?[[:digit:]]{2}$/:
return "Central Bohemian";
break;
# Plzeň region
case /^301[ ]?[[:digit:]]{2}$/:
case /^31[[:digit:]]{1}[ ]?[[:digit:]]{2}$/:
case /^32(0|1|2|3|4|5|6)[ ]?[[:digit:]]{2}$/:
case /^33[[:digit:]]{1}[ ]?[[:digit:]]{2}$/:
case /^34(0|1|2|4|5|6|7|8|9)[ ]?[[:digit:]]{2}$/:
return "Plzeň";
break;
# Karlovy Vary region
case /^35(0|1|2|3)[ ]?[[:digit:]]{2}$/:
case /^35(6|7|8)[ ]?[[:digit:]]{2}$/:
case /^36(0|1|2|3|4)[ ]?[[:digit:]]{2}$/:
return "Karlovy Vary";
break;
# South Bohemian region
case /^37(0|1|2|3|4|5|7|8|9)[ ]?[[:digit:]]{2}$/:
case /^38[[:digit:]]{1}[ ]?[[:digit:]]{2}$/:
case /^39(0|1|2|7|8|9)[ ]?[[:digit:]]{2}$/:
return "South Bohemian";
break;
# Ústí nad Labem region
case /^40(0|1|2|3|5|6|7|8)[ ]?[[:digit:]]{2}$/:
case /^41(0|1|2|3|5|6|7|8|9)[ ]?[[:digit:]]{2}$/:
case /^43(0|1|2|4|5|6|8|9)[ ]?[[:digit:]]{2}$/:
case /^44(0|1)[ ]?[[:digit:]]{2}$/:
return "Ústí nad Labem";
break;
# Liberec region
# Semily district belongs to Liberec region despite its higher zip codes
case /^46(0|1|2|3|4|6|7|8)[ ]?[[:digit:]]{2}$/:
case /^47(0|1|2|3)[ ]?[[:digit:]]{2}$/:
case /^51(1|2|3|4)[ ]?[[:digit:]]{2}$/:
return "Liberec";
break;
# Hradec Králové region
case /^50[[:digit:]]{1}[ ]?[[:digit:]]{2}$/:
case /^51(6|7|8)[ ]?[[:digit:]]{2}$/:
case /^54(1|2|3|4|7|8|9)[ ]?[[:digit:]]{2}$/:
case /^55(0|1|2)[ ]?[[:digit:]]{2}$/:
return "Hradec Králové";
break;
# Pardubice region
case /^53(0|1|2|3|4|5|7|8|9)[ ]?[[:digit:]]{2}$/:
case /^56(0|1|2|3|4|5|6|8|9)[ ]?[[:digit:]]{2}$/:
case /^57(0|1|2)[ ]?[[:digit:]]{2}$/:
return "Pardubice";
break;
# Vysočina region
# Třebíč district belongs to Vysočina region despite its higher zip code
# Pelhřimov district belongs to Vysočina region despite its lower zip code
case /^39(3|4|5|6)[ ]?[[:digit:]]{2}$/:
case /^58(0|1|2|3|4|6|7|8|9)[ ]?[[:digit:]]{2}$/:
case /^59(1|2|3|4|5)[ ]?[[:digit:]]{2}$/:
case /^67(4|5|6)[ ]?[[:digit:]]{2}$/:
return "Vysočina";
break;
# South Moravian region
case /^6(0|1|2|3|4)[[:digit:]]{1}[ ]?[[:digit:]]{2}$/:
case /^66(4|5|6|7|9)[ ]?[[:digit:]]{2}$/:
case /^67(0|1|2|8|9)[ ]?[[:digit:]]{2}$/:
case /^68(0|2|3|4|5)[ ]?[[:digit:]]{2}$/:
case /^69(0|1|2|3|5|6|7|8)[ ]?[[:digit:]]{2}$/:
return "South Moravian";
break;
# Moravian-Silesian region
# Bruntál district belongs to Moravian-Silesian region despite its higher zip code
case /^7(0|1|2)[[:digit:]]{1}[ ]?[[:digit:]]{2}$/:
case /^73(3|4|5|6|7|8|9)[ ]?[[:digit:]]{2}$/:
case /^74(1|2|3|4|6|7|8|9)[ ]?[[:digit:]]{2}$/:
case /^79(2|3|4|5)[ ]?[[:digit:]]{2}$/:
return "Moravian-Silesian";
break;
# Zlín region
# Uherské Hradiště district belongs to Zlín region despite its lower zip code
case /^68(6|7|8)[ ]?[[:digit:]]{2}$/:
case /^75(0|1|2|3|5|6|7)[ ]?[[:digit:]]{2}$/:
case /^76[[:digit:]]{1}[ ]?[[:digit:]]{2}$/:
return "Zlín";
break;
# Olomouc region
case /^779[ ]?[[:digit:]]{2}$/:
case /^78(0|1|2|3|4|5|7|8|9)[ ]?[[:digit:]]{2}$/:
case /^79(0|6|7|8)[ ]?[[:digit:]]{2}$/:
return "Olomouc";
break;
default:
return "NaN";
break;
}
}
You can see that among my awk libraries on github.
I’ve tested this function on roughly 26 000 entries from a real ecommerce database:
#!/usr/bin/awk -f
@include "czech_regions.awk";
BEGIN {
FS="$";
}
{
if (region($3) == "NaN") {
print $3
}
aggregated_sales[region($3)] += $6;
}
END {
for (r in aggregated_sales) {
printf "\"%s\";%.2f\n", r, aggregated_sales[r];
}
}
I focused on those entries that were not mapped with my region() function, this is a complete (not aggregated) list:
35493
73131
24251
77200
75805
77200
35401
35472
35491
68123
354 71
35471
26001
35471
35493
328 00
29601
10,000
77200
44514
77200
65812
772 00
77010
42002
657 70
30000
35491
35472
77200
24801
35491
35491
79,315
73239
73239
35493
30903
20601
73000
35493
77200
48200
35491
12,000
35493
20357
77200
260 71
65520
I randomly tried out a few of these on Google maps and no real Czech area was found based on these numbers, so it seems these are really a mistake (non-existent Czech zip codes). (Of course, on the other hand when Google maps receive a valid zip code, they highlight a specific area in the CZE)
I wish there was a simpler solution to this, but under the current system we use, creating some horrible function as shown above seems the only solution.